

Pythonには最適化計算を回すためのOptunaというライブラリが存在します。
私自身も普段の業務で何度か使ったことがあります。
実際に使ってみて、Optunaは非常に便利なライブラリで非常に使い勝手が良いなと感じました。
今回は、このOptunaを分かりやすく紹介していきます!


“Optuna” とは

Optunaは、ハイパーパラメータの最適化を自動で行ってくれるフレームワークです。
ハイパーパラメータの値を自動的に何度も変化させながら、探索した中で最も優れたパラメータを導き出してくれます。
さらにOptunaは、オープンソースの深層学習フレームワークや様々な機械学習ソフトウェアと一緒に使用することができるため非常に使い勝手の良い最適化フレームワークです。

実際に使ってみて、いろいろな最適化手法が備わっていますし、かなり使いやすく設計されているなと感じました!
機械学習や最適化のアルゴリズムの挙動を制御するパラメータで、アルゴリズム自身で決定できないもの。
そのためハイパーパラメータは、人が手動で設定することが必要となります。
Optunaのライセンス
Optunaのライセンスは、 MIT license です。
“Optuna” のインストール
まずは、Optunaをインストールしましょう!
コマンドプロンプトを開いてpip installするだけで準備OKです!
pip install optuna“Optuna” を実際に使ってみた

二次関数を例にして最適解を求めてみる
まずは簡単な関数を用意して最適化を試みます!
今回は、下記のような二次関数を対象としてy軸の値が最小となるような解をOptunaに導き出してもらおうと思います。
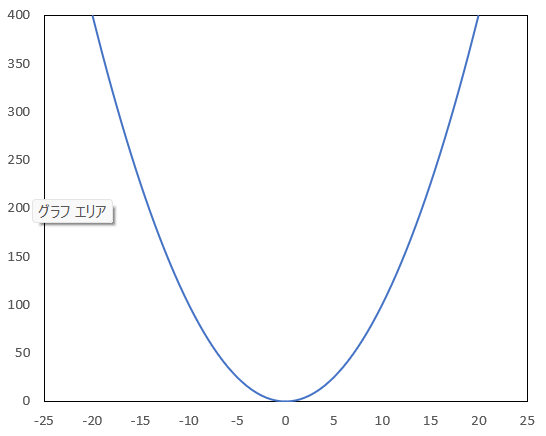
そのため、最適な目的関数値は “0” に近い値が導出されていれば良いということになりますね。
では実際にプログラムを書いて、Optunaが優れた値を導き出してくれるかどうか検証してみます。
- ・ 目的関数:二次関数
- ・ 探索範囲(変数)の値は、浮動小数点型で -10~10
- ・ 探索回数(n_trials)100回
(実際のコード)
import optuna
# 最適化関数
def objective(trial):
# 変数を変化させる
x = trial.suggest_float('x', -10, 10)
# 目的関数を設定
score = x ** 2
return score
# 最適化を実行
study = optuna.create_study(direction="minimize")
study.optimize(objective, n_trials=100)
# 最適解の出力
print(f"The best value is : \n {study.best_value}")
print(f"The best parameters are : \n {study.best_params}")(実行結果)
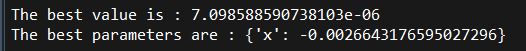
上記プログラムの “最適解の出力” 部分は、それぞれ下記を示しています。
他にも出力可能な最適化計算結果はコチラを確認してみてください。
| study.best_value | 探索した中で最適な目的関数値 |
| study.best_params | “best_value” を出した変数値 |
なのでこの結果を見てみると、100回いろいろな値を探索してみたところ7.099e-6の時に最小の目的関数(優れた解)が得られたことを示しています。
ちゃんと “0” に近い値が出ましたね。
試行回数をより増やせばさらに0に近い値が出力されると思います!
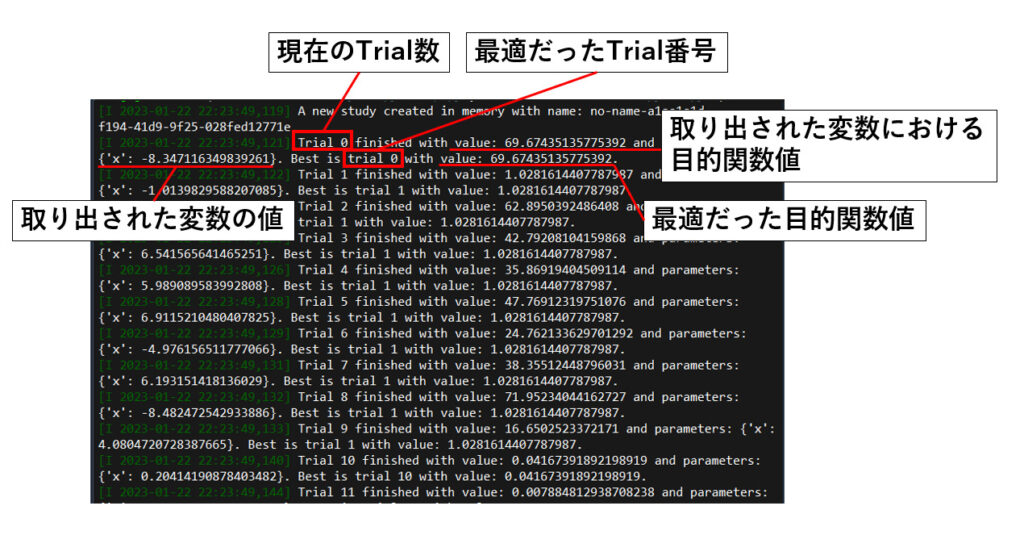
この時、コンソールにもしっかりとTrialの結果が表示されます!
(コンソール表示内容)
また、今回は目的値が ”最小” となるような値を最適値として計算していまいたが
direction=”maximize”
とすることで目的値が “最大” となる値を最適値とすることもできます。
# 望大モデル
study = optuna.create_study(direction="maximize")

その他の探索空間の指定方法
先ほど紹介したプログラムにおけるハイパーパラメータの決定では、
trial.suggest_float ( )としていたので、浮動小数点のパラメータ値が選ばれていました。
その他にも、ハイパーパラメータとして指定できる値はたくさんあるので紹介していきます!
| suggest_int(name, low, high, step=1, log=False) | 整数 |
| suggest_float(name, low, high, *, step=None, log=False) | 浮動小数点 |
| suggest_uniform(name, low. high) | 線形連続値 |
| suggest_loguniform(name, low, high) | 対数区間での連続値 |
| suggest_categorical(name, choices) | カテゴリパラメータ |
| suggest_discrete_uniform(name, low, high, q) | 離散値(ステップ: q) |
ここで、suggest_categorical()の使い方がイマイチ分からないなと思って調べていたら公式サイトに紹介されていましたので記載しておきます。SVCにおけるカーネル関数を定義した例です↓。
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import optuna
X, y = load_iris(return_X_y=True)
X_train, X_valid, y_train, y_valid = train_test_split(X, y)
def objective(trial):
kernel = trial.suggest_categorical("kernel", ["linear", "poly", "rbf"])
clf = SVC(kernel=kernel, gamma="scale", random_state=0)
clf.fit(X_train, y_train)
return clf.score(X_valid, y_valid)
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=3)目的関数が高次元の場合の指定方法
ハイパーパラメータを複数扱いたい場合は下記のようにして、定義すればよさそうです。
x1 = trial.suggest_float(name1, low1, high1)
x2 = trial.suggest_float(name2, low2, high2)最適化結果の詳細確認
Optunaで最適計算した結果は、Studyに保存されます。
計算をした結果、どのようなパラメータが保存されているかを紹介します。
| study.best_params | 最良パラメータを返す |
| study.best_value | 最適な目的値を返す |
| study.best_trial | 最良な目的関数が得られた試験数を返す |
| study.best_trials | パレートフロント解の試験数を返す |
| study.trials | 試験回数を返す |
| study.direction | 最適化の方向を返す |
| study.directions | 最適化の方向を返す |
| study.system_attrs | システム属性を返す |
| study.user_attrs | ユーザー属性を返す |
Optunaはいちいち自分で最適値を更新していくプログラムを組まなくても自動最適値を更新していってくれるようです!
上記のコマンドを使えば、探索結果を簡単に検索することができますね!
スポンサーリンク
スポンサーリンク
Sampler ‐ 最適化アルゴリズムについて

異なるSamplerを使用したいとき
最適解を求めていく際の最適化アルゴリズム(Sampler)において、デフォルトではTPESamplerが選ばれるようですが、任意のアルゴリズムを指定することもできます!
最適化アルゴリズム(Sampler)の指定方法は、引数にSampler=***を追加することで指定できます。
optuna.create_study(Sampler = optuna.samplers.***)
実際に2つほど例を挙げてみます!
(例1)
# 例1 RandomSamplerを指定したい場合
study = optuna.create_study ( sampler=optuna.samplers.RandomSampler() )(例2)
# 例2 NSGAIIを指定したい場合
study = optuna.create_study(sampler=optuna.samplers.NSGAIISampler())Optunaで下記のSamplerは使用できるみたいです!
| GridSampler | |
| RandomSampler | |
| TPESampler | |
| CmaEsSampler | |
| PartialFixedSampler | |
| NSGAIISampler | |
| QMCSampler | |
| BoTorchSampler | |
| BruteForceSampler |
最適化アルゴリズムの選定方法
先ほど紹介したSamplerは目的に応じて適切に選定していく必要があります!
それぞれ、特徴が異なるので紹介していきます!
| RandomSampler | GridSampler | TPESampler | CmaEsSampler | NSGAIISampler | QMCSampler | BoTorchSampler | BruteForceSampler | |
|---|---|---|---|---|---|---|---|---|
| suggest_float | 〇 | 〇 | 〇 | 〇 | ▲ | 〇 | 〇 | 〇( × 無限整域) |
| suggest_int | 〇 | 〇 | 〇 | 〇 | ▲ | 〇 | 〇 | 〇 |
| suggest_categorical | 〇 | 〇 | 〇 | ▲ | 〇 | ▲ | 〇 | 〇 |
| Pruning | 〇 | 〇 | 〇 | ▲ | × | 〇 | ▲ | 〇 |
| 多変量最適化 | ▲ | ▲ | 〇 | 〇 | ▲ | ▲ | 〇 | ▲ |
| Conditional Search Space | 〇 | ▲ | 〇 | ▲ | ▲ | ▲ | ▲ | 〇 |
| 多目的最適化 | 〇 | 〇 | 〇 | × | 〇 (▲ 単目的の場合) | 〇 | 〇 | 〇 |
| バッチ最適化 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | ▲ | 〇 |
| 分散最適化 | 〇 | 〇 | 〇 | 〇 | 〇 | 〇 | ▲ | 〇 |
| 制約付き最適化 | × | × | 〇 | × | 〇 | × | 〇 | × |
〇:適用可 ▲:適用可だが非効率 ×:エラーが発生もしくはインターフェースなし
Reference:Optuna.samplers instruction
この表を見てみると、すべてのSamplerがどのようなモデルにも適用できる訳ではなく、用いるパラメータの型や最適化したいモデルの種類によって適切なものを選定する必要がありそうです。。。
Optunaで枝刈り(Pruner)する方法
最後になりますが、Optunaには枝刈り機能を付け加えることができます。
深層学習や、勾配ブースティング及び反復試行などに用いられる場合、学習の途中で見込みのない試行は途中で処理を打ち切ってしまって、短時間で効率的に探索を進めようという機能です。
枝刈り(Pruner)を使用する場合には、下記のようにオプションを指定します。今回はMedianPruner()を指定してみます。
study = optuna.create_study(pruner=optuna.pruners.MedianPruner())Prunerは他にも様々な種類があり、用いる目的や最適化問題に合わせて適したものを選定する必要があります。
| MedianPruner |
| NopPruner |
| PatientPruner |
| PercentilePruner |
| SuccessiveHalvingPruner |
| HyperbandPruner |
| ThresholdPruner |
公式サイトによると、
ほとんどの場合、MedianPrunerを用いるそうです。
基本的に、MedianPrunerはSuccesiveHalvingPruner及びHyperbandPrunerよりも優れているそうです。
ただ、PrunerとしてTPESamplerを用いる場合はHyperbandPrunerが最適だそうです。
詳しくはOptuna公式サイトを確認してみてください!
ノーフリーランチの定理
ノーフリーランチの定理とは、要約すると「うまい話なんてない」という意味です。今回のような最適化問題においては「万能なアルゴリズムなんてない」 ということを言っています。
つまり、アルゴリズムを選定する上では何が最適なのかを色々と試してみる必要があるということです。
大変ですが機械学習や最適化をする際には、アルゴリズムをいくつかに絞った上で一つずつ検証していく必要がありそうです。。。
万能な探索アルゴリズム、、、欲しいですよね、、、
以上となります、最後まで見ていただきありがとうございます!
Python学習に役立つ書籍も紹介しています!






















