
Excelは、表計算やデータ処理およびデータの記録などを手軽に行うことができるので非常に便利ですよね。
ここでExcelに記録したデータをPython上でも扱うことができれば、機械学習やデータ分析を行うことができるため非常に便利です。

今回は、Excelデータ(CSV形式)をPython上に取り込む方法を解説していきます!

CSVデータを読み込む

pandasでCSVを読み込む
では早速CSVデータをPythonで読み込んでみましょう。
今回読み込むCSVファイルは下記のようなデータシート(practice.csv)とします。
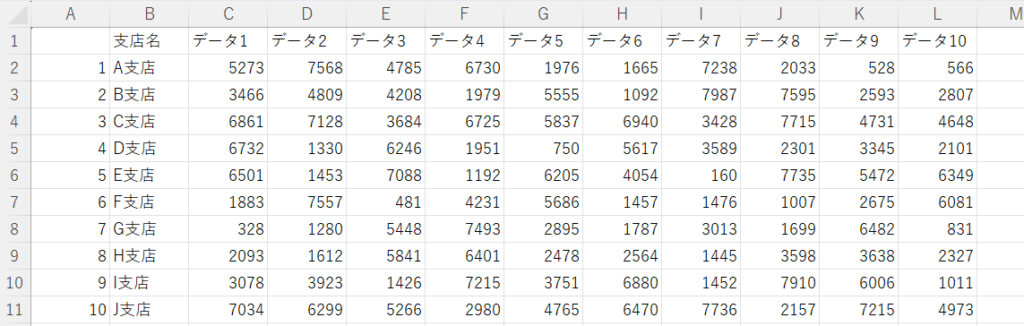
Pythonを用いてCSVデータを読み込む際には、下記コードのように”pd.read_csv”を用います。
pandasは、Pythonでデータ分析を効率的に行うためのライブラリのことでデータ分析や統計処理を無料で行うことができるものです。
import pandas as pd
df=pd.read_csv(”読み込みたいCSVデータまでのパス”)ここで”読み込みたいCSVデータまでのパス”は、絶対パスを入力すると良いです。
例えばデスクトップに保存してあるpractice.csvというファイルを読み取りたい場合の絶対パスは、このようなパスになります。
“C:\Users\Desktop\practice.csv”
読み込み時にエラーが出た場合
上述したコードを実行しても、CSVデータが読み込まれない場合は下記に示す方法を試してみましょう!
■SyntaxError:がでたときの対処法
プログラムを実行した際に、
というエラーが表示された場合は、パス(おそらく”\”)が上手く読み込めていないことが原因です。
そのためパスの頭に r を付けることで”\”を読み込めるようにします。
df=pd.read_csv(r"C:\Users\Desktop\practice.csv")(※ “\” が “¥” と表示されています。)
■UnicodeDecodeError:がでたときの対処法
プログラムを実行した際に、
というエラーが表示された場合はどうやら、文字コードの読み込みができないということを示しています。
プログラミングの一般的な文字コードは“utf-8”らしいのですが、このままでは日本語がファイル名やパス名に入っている場合に文字コードを読み込めなくなるようです。
そのため、日本語でも対応してくれるように”pd.read_csv”の引数として”shift-jis”を追加してエンコーディング(文字コードの変換)を行うことでエラーを解消することができます。
import pandas as pd
df=pd.read_csv(r"C:\Users\Desktop\practice.csv", encoding="shift-jis")CSVの読み込み結果

では実際にPythonで読み込んだ結果を紹介していきたいと思います。
”pd.read_csv”メソッドでCSVデータをPython上に読み込むと下図のようなpandasのDataframeという形式で保存されます。

このDataframeという形式はデータ編集において非常に使い勝手が良いです!
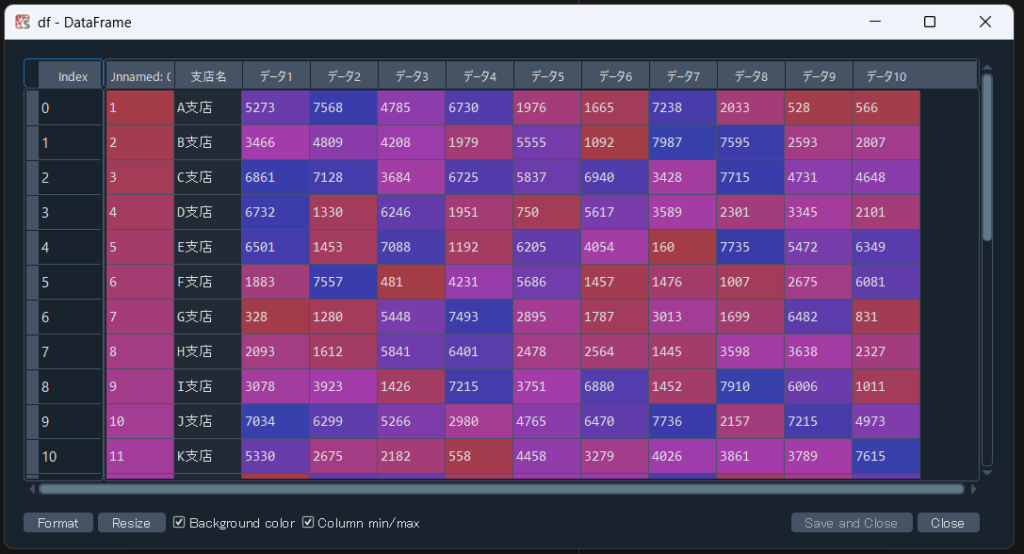
(※この実行結果はSpyderで処理を実行した結果を示しています。)
このように読み込むことができました!
良く見ると、CSVデータの一行目は下図の赤枠①に示すようにindexとしてDataframeに入力されていることが分かります。また、一列目に関しては赤枠②に示すようにCSVデータの一列目とは別でセル番号がindexとして入力されています。

CSVデータの一行目をindexとして読み込みたい場合はコチラ


読み込んだDataframeの操作方法

指定したセルや行を取得する
■セルの値を読み取る
セルの値を取得する場合には、”at”,”iat”を使います。
- at:行ラベル,列ラベルを指定する
- iat:行番号,列番号を指定する
今回は、赤枠で示した「7557」という数字を読み取ってみたいと思います。
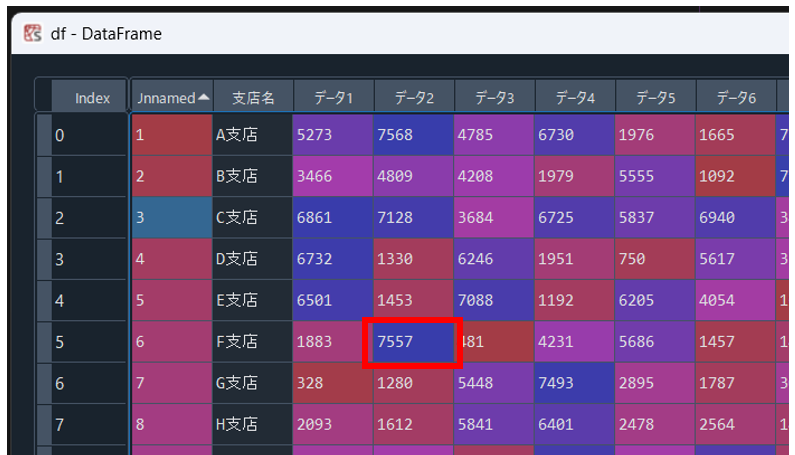
print(df.at[6,"データ2"]) #取得したいセルの行・列ラベルを指定
print(df.iat[5,3]) #取得したいセルの行・列番号を指定「at」「iat」のどちらを用いて取得してもOutputは「7557」となります。
ただし、iatを用いる場合のセル番号は、行・列ともに0始まりだということに注意しましょう!
■行を取得する
行を取得する場合には、”loc”,”iloc”を使用します。
- loc:取得したい行を、行ラベルで指定する
- iloc:取得したい行を、行番号で指定する
今回は、赤枠で示したように上から3行目のC支店のデータを取り出してみたいと思います。
※分かりやすくするためindexを支店名にしています。
indexを変える方法はコチラ。

data1=df.loc["C支店":"C支店"] #locを用いた場合
data2=df.iloc[1:2] #ilocを用いた場合ここで、”loc“や”iloc“の [ ] の中はどの行からどの行までを取得するのかを指定しています。ただし、”loc“と”iloc“では上記のように指定の仕方に少し違いがあるみたいです。
どちらも正しく取得できました!

また、取得したい行が例えば「C支店までのデータ」あるいは「C支店以降のデータ」である場合は下記のように指定することで取得することができます。


#C支店までを取得したい場合
data1=df.loc[:"C支店"]
data2=df.iloc[:3]
#C支店以降を取得したい場合
data1=df.loc["C支店":]
data2=df.iloc[2:]ただし、locを用いて取得する場合とilocを用いて取得する場合では、行番号の指定の仕方に差異があるので注意しましょう。。。

一列目をインデックスとして読み込む方法
CSVデータをそのまま読み込むと、行のindexはセル番号が自動で割り振られてしまいます。これに対してCSVの一列目をindexとして読み込みたい場合は”pd.read_csv”の引数として”index_col=0“を指定します。
ここで指定した数字は、CSVの列番号です。
import pandas as pd
df=pd.read_csv(r"C:\Users\Desktop\practice.csv", index_col=0)すると実行結果はこのようになります。
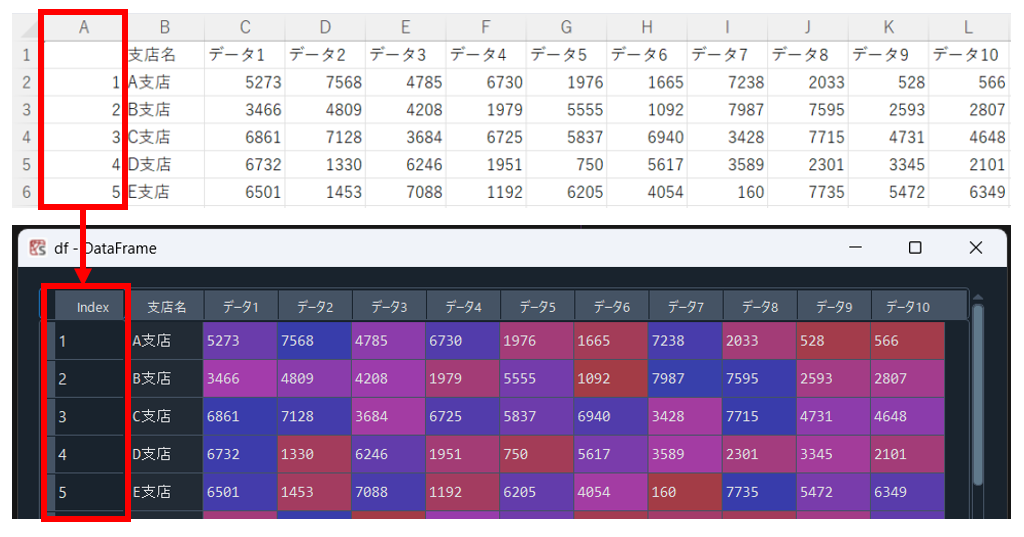
また、”index_col=1“とすると支店名の欄をindexとすることもできます!
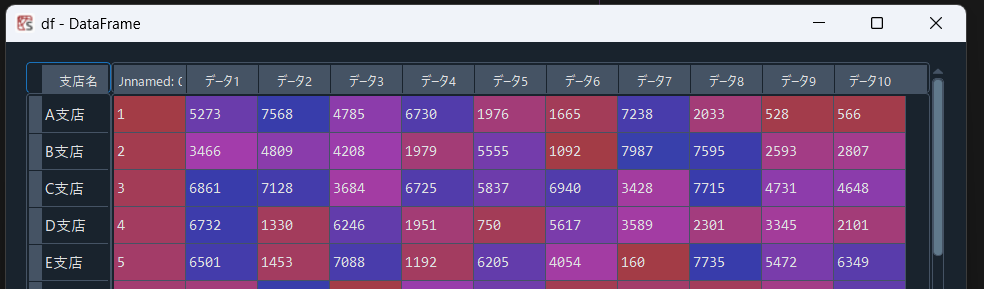
データを昇順・降順で並び替える
Dataframeとして取得したデータにおいて、任意の列を昇順もしくは降順に並び替えたい場合は”sort_values”メソッドを使用します!
今回は「データ2」の列を並び替えていきたいと思います!
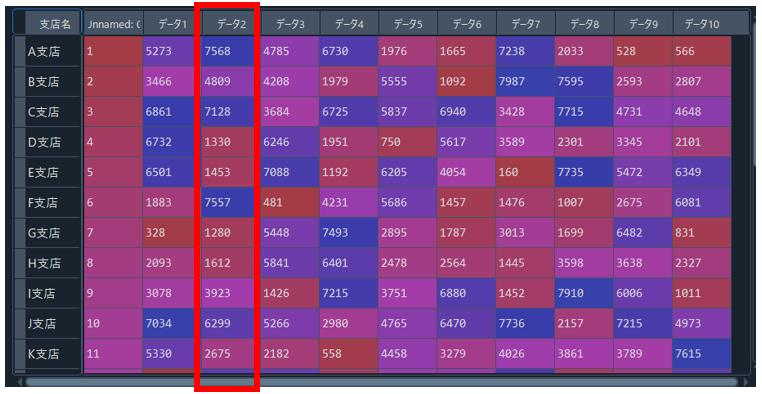
■昇順
任意の列を昇順に並び替えたい場合は、”sort_values”の引数として第一引数に並び替えたい列を指定し、第二引数として”ascending=True”を指定してあげます。
df=pd.read_csv()
df_up=df.sort_values("データ2",ascending=True)すると実行結果はこのようになり、「データ2」という列のデータを昇順に並び替えることができました。
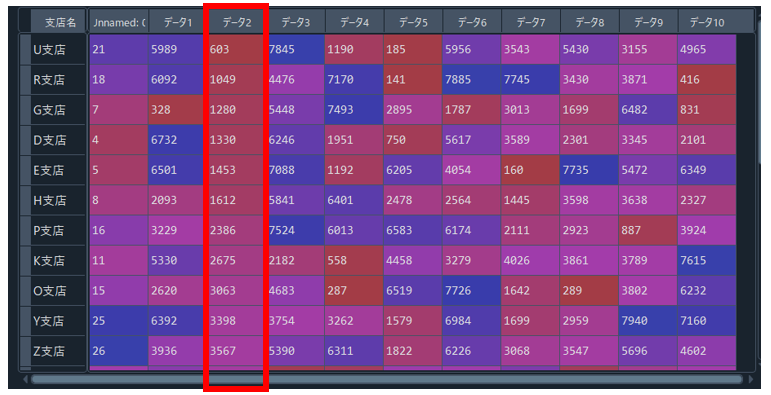
■降順
続いて、降順に並び替える方法を紹介します。
任意の列を降順に並び替えたい場合は、”sort_values”の引数として第一引数に並び替えたい列を指定し、第二引数として”ascending=False”を指定してあげます。
df=pd.read_csv()
df_down=df.sort_values("データ2",ascending=False)すると実行結果はこのようになり、「データ2」という列のデータを降順に並び替えることができました。

以上となります。
最後まで見ていただきありがとうございました!
別記事で人気のプログラミングスクールや書籍を紹介していますので是非見てみてください!




















