
今回はPythonを用いてWEBスクレイピングを行います。
WEBスクレイピングとは、WEBサイトから大量の情報を自動的に抽出することができる技術のこと。WEBサイトやデータベースを探り、大量のデータの中から特定のデータのみを特定して抽出することができます。
例として、Yahoo Newsの主要News欄をPick upして表示させてみます!
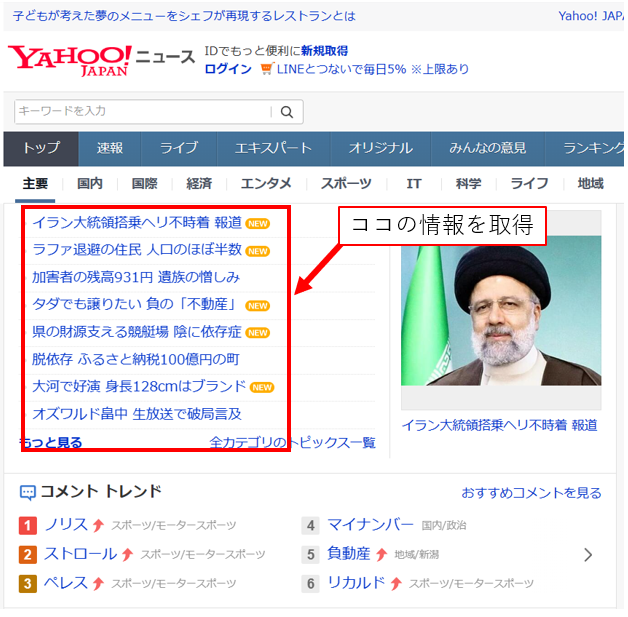

では実際にコードを紹介していきます。

Yahoo newsの主要Newsを取得する

WEBスクレイピングに用いるモジュール
まずは、今回のスクレイピングで用いる核となるライブラリは「beautifulsoup4」と「requests」の2つが必要になります。
ライブラリのインストール
これらをインストールする際には、Macであればターミナルから、Windowsであればコマンドプロンプトからpipコマンドよりインストールできます。
pip install requestspip install beautifulsoup4このrequestsとbeautifulsoup4のライブラリ内の「BeautifulSoup」というモジュールを用いてWEBスクレイピングを行っていきます。
BeautifulSoupを用いて主要Newsを取得する
実際のコード
では実際に簡単なコードを交えて紹介していきます!
Yahoo Newsを取得するコードは下記のように書くことができます。
import requests
import re
import unicodedata
from bs4 import BeautifulSoup
def main():
# URLの取得------------
url = "https://news.yahoo.co.jp/"
# cnt=0
# --------------------
# HTMLの取得
r = requests.get(url)
html = r.text
# 日本語文字化け防止
r.encoding = r.apparent_encoding
# BeautifulSoupクラスのインスタンス化
soup = BeautifulSoup(html, "html.parser")
# 取得したいnewsの塊を取得
topic = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
#取得したデータを格納する配列
news_list=[]
for i in topic:
# 日本語がない場合処理Skip
if ck_japanese(i.contents[0])==False:
continue
else:
news_list.append(i.contents[0])
#取得したnewsのデータを表示
print(news_list)
# テキストが日本語かどうかの判定
def ck_japanese(string):
for ch in string:
name = unicodedata.name(ch)
if "CJK UNIFIED" in name \
or "HIRAGANA" in name \
or "KATAKANA" in name:
return True
return False
if __name__=="__main__":
main()コードの解説
先ほど紹介したコードの中の下記部分を説明していきます。
① HTMLの取得
r = requests.get(url)
html = r.text
② 日本語文字化け防止
r.encoding = r.apparent_encoding
③ BeautifulSoupクラスのインスタンス化
soup = BeautifulSoup(html, "html.parser")
④ 取得したいnewsの塊を取得
topic = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))①HTMLの取得
r = requests.get(url)
html = r.textここでは、requests.get(url)を使用して引数として使用したWEBページの全ての情報を取得することができます。
2行目では、取得した情報をテキスト形式に変換しています。
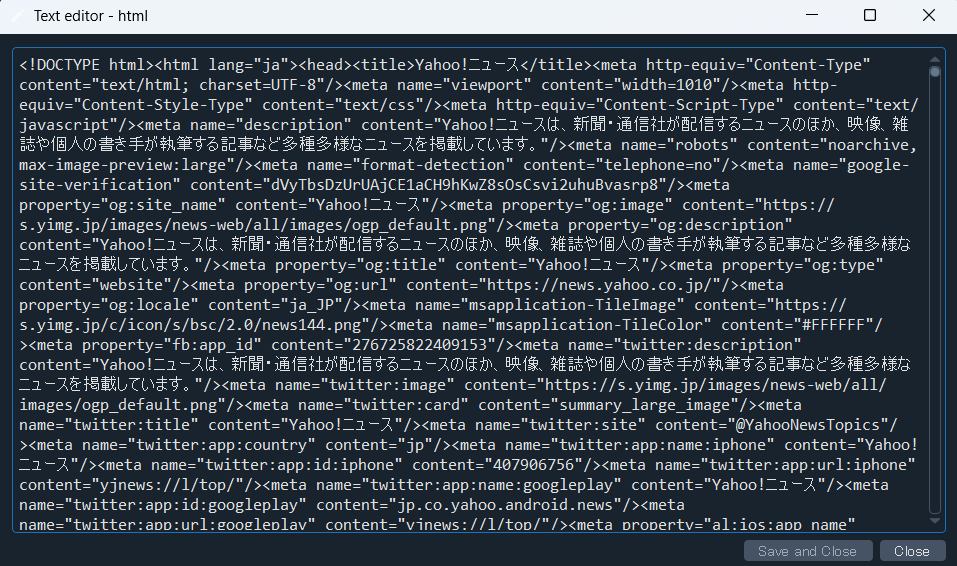
実際にt.textを実行した後のデータはこのようにWEBサイトの情報がテキスト形式で保存されます。
②日本語文字化け防止
ここでは、WEBサイトから取得した情報において日本語が文字化けしないようにしています。
③BeautifulSoupクラスのインスタンス化
soup = BeautifulSoup(html, "html.parser")ここではBeautifulSoupモジュールを使用してHTMLからデータを取得しています。
第一引数には、テキスト形式のHTMLもしくはXMLを渡します。
第二引数には、第一引数として渡したデータを解析するために「.parser」というメソッドを使用します。HTMLを用いた場合は「html.parser」「xml.parser」を渡します。
これらの引数を渡してインスタンスを作成してあげます。そして作成したインスタンスを用いて取得したいデータを抽出します。
④取得したいnewsの塊を取得
topic = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))まず、Yahoo Newsの主要Newsが閲覧できるURLが「news.yahoo.co.jp/pickup」です。
そのためこのURLを「.find_all()」メソッドを用いてhtmlデータ内におけるhref属性として「news.yahoo.co.jp/pickup」が含まれる行を抽出してくれます。
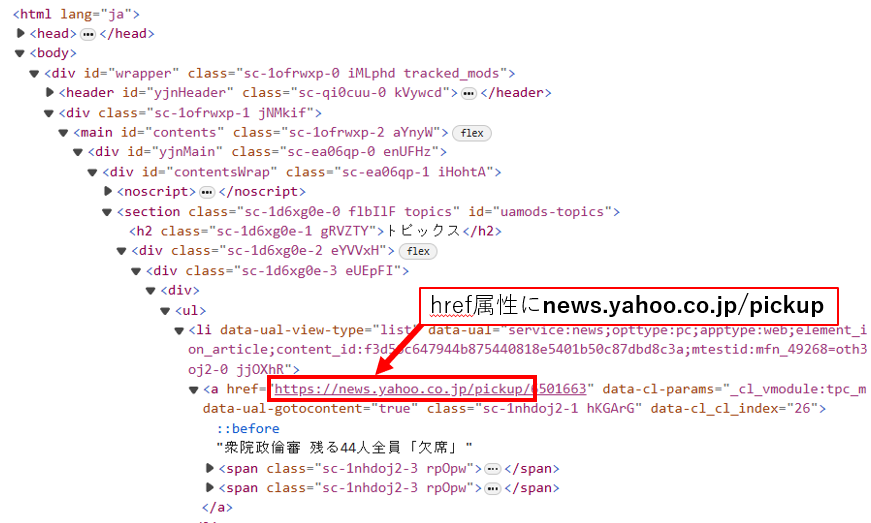
☆href属性の確認方法
href属性は、確認したい部分で右クリックをしてMicrosoft Edgeの場合はWEBサイトの「開発者ツール」で確認することができます。Chromeの場合は「検証」というところをクリックすることで確認できます。
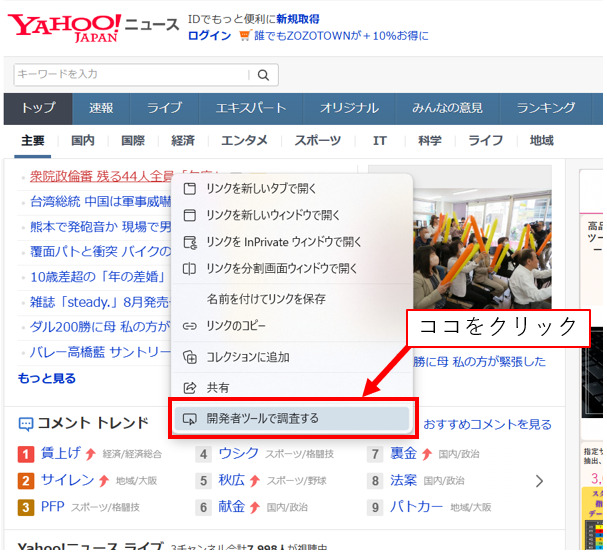
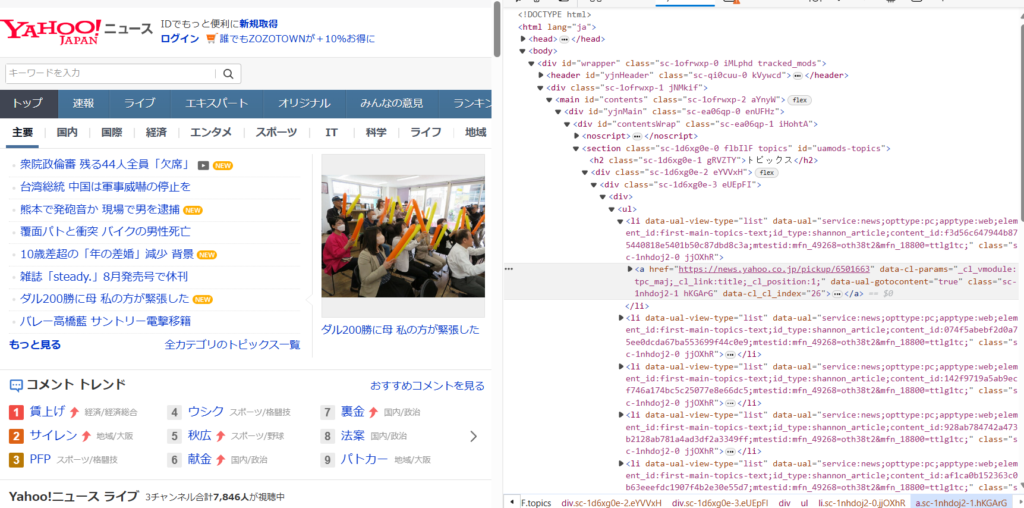
上記のように表示されたコードを確認すると、今回抽出したい主要Newsの情報が「news.yahoo.co.jp/pickup」という部分にあることが確認できます。


Tkinterを用いてGUI上に表示

では先ほどまで紹介したスクレイピング手法を用いて、より分かりやすくGUI上に表示させてみます。
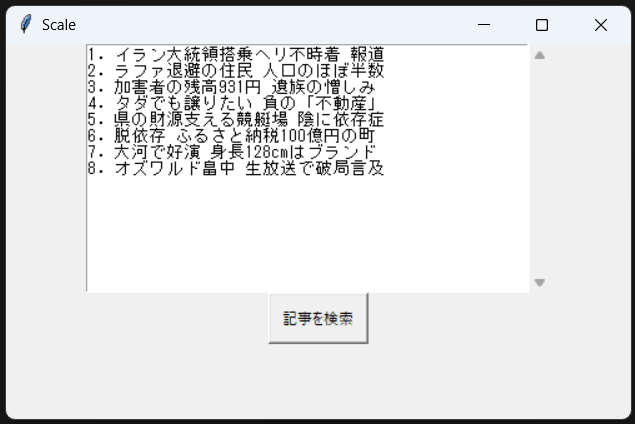
実際にコードは下記のようになります。
import tkinter as tk
import requests
import re
import unicodedata
from bs4 import BeautifulSoup
from tkinter.scrolledtext import ScrolledText
def main():
#GUI window作成
root = tk.Tk()
root.title('Scale')
root.geometry("500x300")
#textboxの配置
textbox1 = ScrolledText(root, height=15,width=50)
textbox1.pack()
#buttonの配置
button1 = tk.Button(root, text="記事を検索", width=10, height=2, command=lambda: push_button(textbox1))
button1.pack(anchor='center')
root.mainloop()
def push_button(textbox1):
# URLの取得------------
url = "https://news.yahoo.co.jp/"
cnt=0
# --------------------
# HTMLの取得
r = requests.get(url)
html = r.text
# 日本語文字化け防止
r.encoding = r.apparent_encoding
# BeautifulSoupクラスのインスタンス化
soup = BeautifulSoup(html, "html.parser")
# 取得したいnewsの塊を取得
topic = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
for i in topic:
# 日本語がない場合処理Skip
if ck_japanese(i.contents[0])==False:
continue
else:
cnt += 1
#textboxに一つずつ改行して表示
textbox1.insert(tk.END,str(cnt) + '. ')
textbox1.insert(tk.END, i.contents[0])
textbox1.insert(tk.END,'\n')
# テキストが日本語かどうかの判定
def ck_japanese(string):
for ch in string:
name = unicodedata.name(ch)
if "CJK UNIFIED" in name \
or "HIRAGANA" in name \
or "KATAKANA" in name:
return True
return False
if __name__=="__main__":
main()以上になります。
最後まで見ていただきありがとうございました!
皆様の参考となれば幸いです。他にも記事を紹介していますのでお時間があれば是非ご覧ください。





















